2024年10月9日,诺贝尔化学奖被授予蛋白质设计先驱 David Baker,以及谷歌DeepMind的 Demis Hassabis和John Jumper,以表彰他们在计算蛋白设计和蛋白结构预测领域的巨大贡献。

(图片:https://www.nobelprize.org/prizes/chemistry/2024/summary/)
我们知道,Alphafold3可以准确预测众多蛋白甚至蛋白-小分子、核酸复合物的结构,计算蛋白设计也已经被广泛应用于蛋白binder、酶、跨膜蛋白、变构蛋白等的设计。抗体作为蛋白质的一种特殊形式,在生物医药领域占据半壁江山,全球市场规模已达到数千亿美元。AI蛋白结构预测、计算蛋白设计技术能应用于抗体吗?与其他蛋白相比,有什么不同之处?如何设计抗体?抗体从头设计技术的成熟度如何?应用现状如何?发展前景如何?
本文简要总结了科迈生物3年来的工作成果,试图较为系统地回答上述问题。对于AI蛋白结构预测和蛋白设计的公开介绍文章已经有很多,本文不再赘述,而是将重点放在抗体的AI从头设计领域。通过阅读本文,您将了解到以下内容:
蛋白结构预测与计算蛋白设计的区别与联系,抗体从头设计的难点
为什么要进行抗体从头设计?主流抗体发现方法的优缺点,靶向特定抗原表位的重要性
如何进行抗体从头设计?数据收集、AI模型训练与计算流程的搭建
目前AI抗体从头设计的成功率达到了什么水平?科迈生物的多个成功案例展示
该领域的的挑战、发展趋势和应用前景
全文约9000字,预计阅读时长20分钟。
蛋白结构预测与蛋白设计区别与联系

为什么说抗体从头设计比普通的蛋白binder设计要困难得多
● 准确预测抗体结构非常困难。这里主要指CDRH3的部分,也是抗原-抗体结合的关键位置。CDRH3为loop构象,柔性较大,不是稳定的二级结构(alpha helix/beta sheet等),没有特别明确的从序列到结构的规律
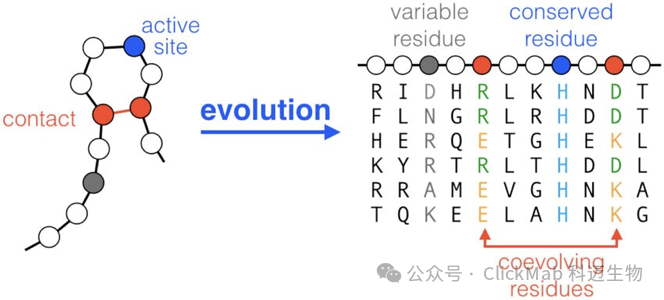
(图片:Cocco S, Feinauer C, Figliuzzi M, et al. Inverse statistical physics of protein sequences: a key issues review[J]. Reports on Progress in Physics, 2018, 81(3): 032601.)
既然抗体从头设计这么困难,而且目前已经有比较成熟的抗体发现手段了(基于动物免疫的杂交瘤、免疫库筛、单B细胞筛选等,基于合成和半合成的库筛等),为什么还要研究从头设计呢?解决这个问题的意义和价值是什么?这就不得不提靶向特定表位的抗体在抗体药物研发中的重要性。
特定抗原表位对抗体药物的重要性
从抗体药物研发的角度来看,抗体从头设计解决的一个核心问题是,如何精准可控地获得靶向指定抗原表位的抗体。为什么我们需要如此关注抗原表位?因为抗体结合的表位不同,药效甚至安全性都会不同。

以CD73靶点为例,CD73是一种酶,负责将AMP水解成腺苷,它在肿瘤免疫中扮演着重要角色。CD73蛋白具有特殊性,因为它的非活性构象与活性构象之间的差异较大。非活性构象是开放的,而活性构象则在N端形成闭合,只有在闭合状态下,底物结合位点才能形成并发挥催化作用。
因此,结合N端的表位可能不是最佳选择,因为它可能导致不同的结合模式,进而在不同抗体浓度下对酶活性的抑制效果产生浓度依赖性。在1:1的化学当量比下,为结合模式2,抗体可能达到最佳的抑制效果;但如果抗体浓度过高或过低,会变成结合模式1,抑制效果会下降,且无法实现100%的酶活性抑制。这种情况的典型代表是抗体MEDI9447。
当前主流抗体发现方法的缺陷
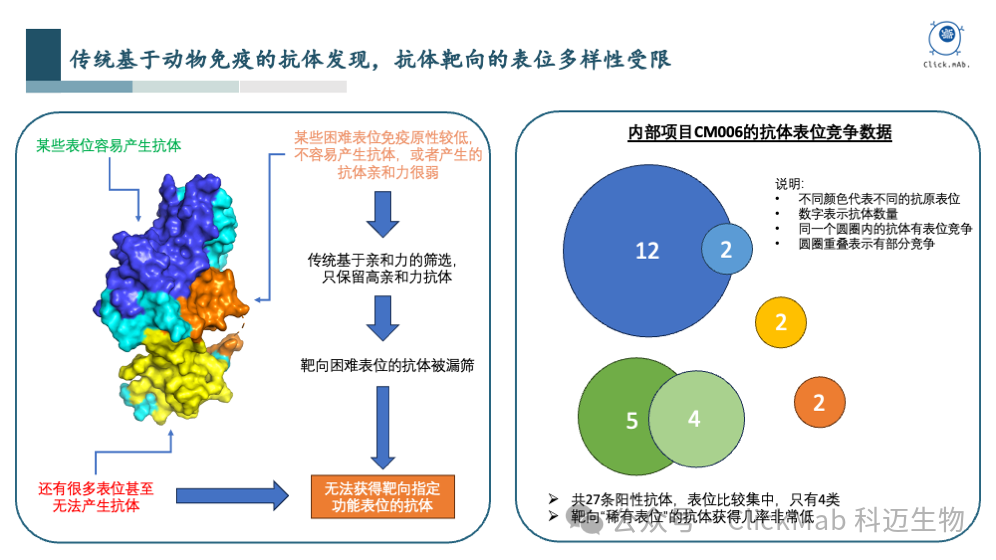
以科迈生物的内部项目CM006为例,利用抗原免疫小鼠获得了27条阳性抗体,通过表位竞争实验,可以看到这些抗体结合到了四类表位,而且分布非常不均匀,绝大部分抗体集中在2个表位上,剩余的2个“稀有表位”只有2条抗体。如果我们需要的生物学功能相关表位恰好集中在“稀有表位”,甚至其他未被覆盖到的表位,那么候选抗体数量就会非常少,甚至没有候选抗体,难以有效推进抗体药物的管线。

在上图中,我们总结了当前主流的三种抗体发现手段的优缺点。如果抗体来自动物免疫的方法,对于暴露程度低、免疫原性低、难以制备的抗原等,均会面临挑战。当前主流方法在筛选抗体时,主要基于亲和力而非特定表位,这可能导致初期筛选出的抗体亲和力虽好,但后续药效不佳。

这种方法的最大特点是无需动物免疫,不依赖于从动物体内筛选抗体,而是直接通过AI针对特定表位生成全新的抗体。它不是基于已知抗体进行优化,而是从零开始创造新的抗体,以满足靶向特定表位的需求。一旦实现该流程,现有的抗体发现过程将被重塑,真正实现从生物学功能需求出发,“指哪打哪”,理性设计抗体。
特定表位抗体从头设计底层原理和思路
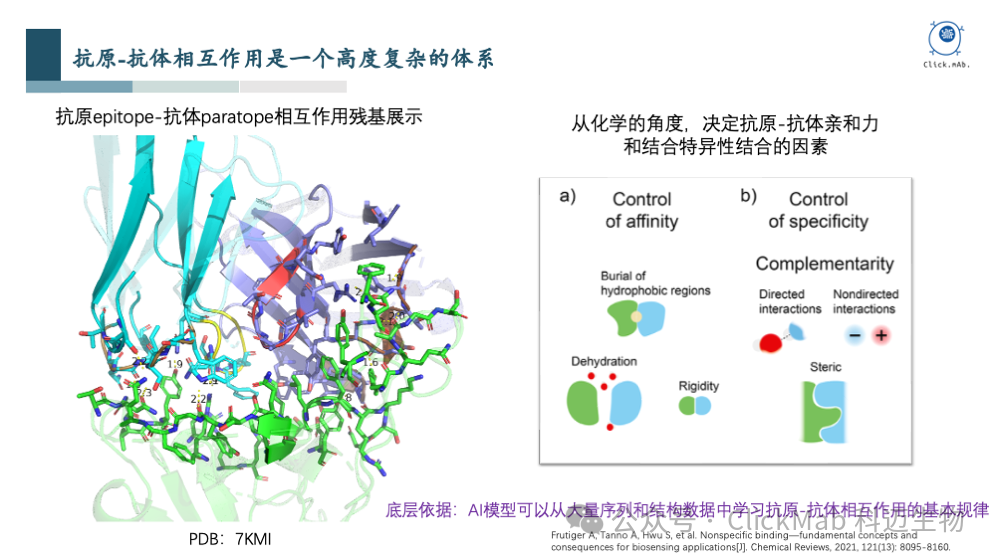
上述图片中,左图是抗原抗体复合物结构中相互作用的界面,涉及到几十个残基的相互作用,非常复杂,人类很难进行修改和优化,更不用说从头设计;从化学的角度来看,抗原抗体之间的相互作用,实际上是由底层的物理规律决定的。可以看到,一方面规律是存在的,另一方面该规律非常复杂,人工难以学习。如果您对AI有所了解,就会意识到,如果能收集大量数据的话,这个场景是非常适合利用AI来解决的,因为AI非常擅长从大量数据中学习复杂的规律,并进行预测和生成。
以上是最底层的原理,但落实到具体问题上,应该怎么做呢?这里给大家介绍一下当时思考这个问题的思路:
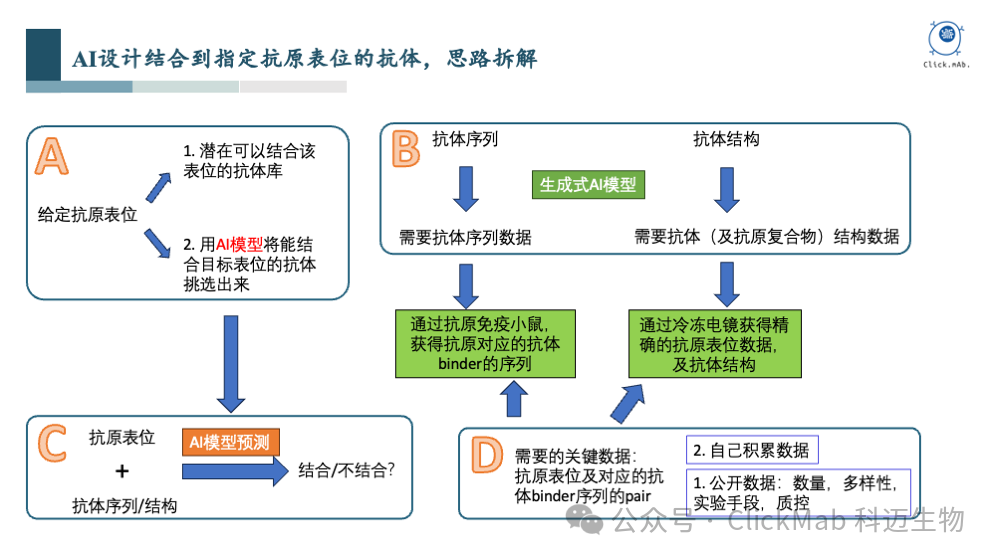
在这个问题中,我们已经给定了抗原表位。一个非常简单的想法是,如果我们有一个包含潜在结合该表位的抗体库,另外又有一个AI模型,能够准确分辨这个库中哪些抗体可以结合到目标表位, 那么该问题就解决了
我们如何构造该抗体库呢?从抗体序列和抗体结构的角度考虑,如果我们能够收集大量的抗体序列数据和结构数据,就可以训练生成式AI模型,生成抗体序列和结构库。这就涉及对于大量序列和结构数据的收集
我们如何构造和训练该AI模型?经过反复思考,我们认为这个关键模型的输入应该是抗原表位和给定抗体的序列或结构,输出是预测抗体与抗原表位是否结合
为了训练该AI模型,我们需要什么样的数据呢?实际上就是抗原表位和对应的能结合到该抗原表位的抗体binder的序列或结构
从哪里获得数据呢?最先想到的是公开数据,PDB、SabDab、OAS等数据库中已经有一些抗体的序列和结构数据,但数据多样性、质量和数量等,均无法满足我们的要求,所以我们决定自己内部积累数据
我们如何内部积累这些数据?一方面我们通过挑选多样化的抗原免疫小鼠,获得阳性抗体binder的数据, 增强模型的泛化能力;另一方面,我们挑选部分代表性抗体,通过冷冻电镜获取抗原抗体复合物的结构。完成大量序列和结构数据的积累后,就具备了训练AI模型解决抗体从头设计问题的前提条件
数据收集和AI模型训练的过程
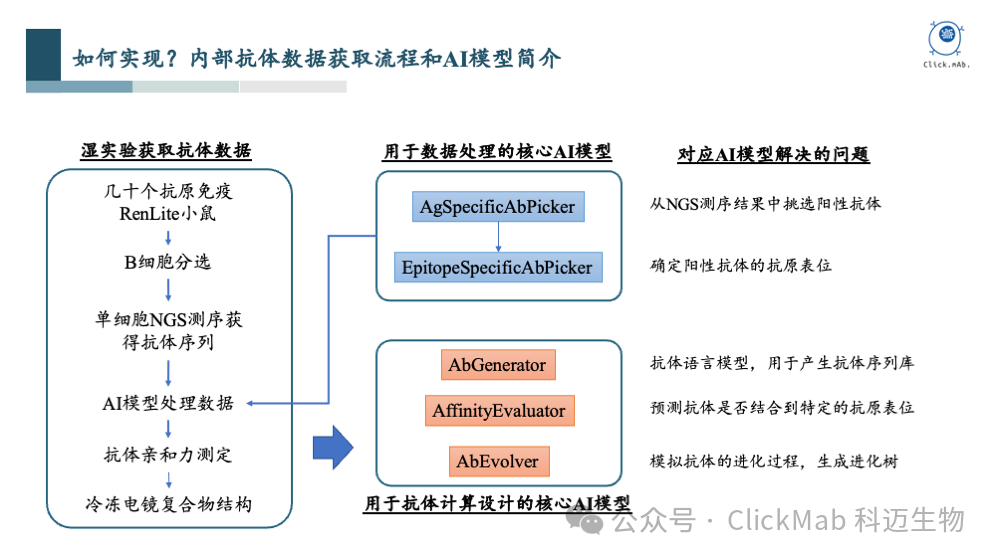
实现抗体设计的过程可以大致分为几个部分。首先,我们需要收集和获取数据。我们通过抗原免疫小鼠来实现这一步骤。具体来说,我们选择了几十个抗原蛋白进行免疫,使用百奥赛图的全人源RenLite小鼠。免疫后,我们取小鼠的脾脏和淋巴结进行破碎处理,并通过FACS分离出B细胞,以及抗原特异性B细胞,这些B细胞被认为能够结合到抗原上。
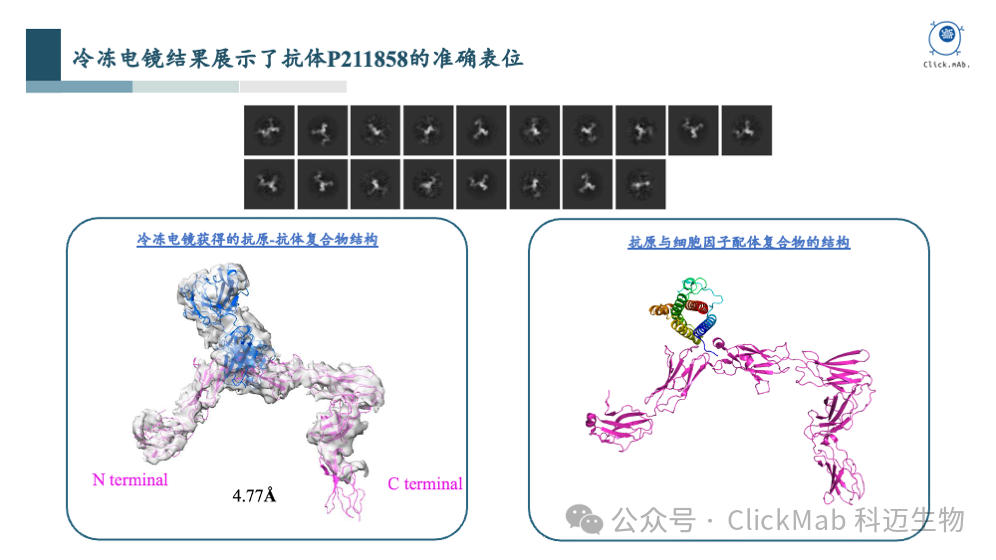
我们挑选了一些具有代表性的阳性抗体,并通过冷冻电镜技术获得了抗原-抗体复合物的高分辨率结构,这对后续AI模型的训练非常有帮助。
我们开发了一个抗原表位预测模型,称为EpitopeSpecificAbPredictor,它可以帮助我们预测给定的抗体序列结合到抗原的哪个表位上。在测试集中,我们的成功率(precision)可以达到78%,而AF2-multimer的成功率为50%。该表位预测模型已经上线到科迈的AI抗体设计平台(www.clickmab.com),供大家免费使用。下面是一些预测的实例,供大家参考:

以上是数据积累的部分,接下来是我们的AI模型。在整个抗体从头设计流程中,核心AI模型有3个:
序列生成模型AbGenerator:这个模型类似于当前流行的语言模型ChatGPT,但它学习的是抗体氨基酸序列的规律。我们知道,抗体序列有其内在的规律,如某些区域保守,而某些区域(特别是CDR H3区)多样性很高。序列模型可以学习在特定位置上哪种氨基酸出现的频率,以及氨基酸之间的依赖关系。基于这些规律,模型能够生成新的抗体序列,这些序列通常是基于全人源抗体训练的,因此具有全人源特性。该模型的文章已经正式发表(Gao X, Cao C, He C, et al. Pre-training with a rational approach for antibody sequence representation[J]. Frontiers in Immunology, 15: 1468599.),欢迎大家使用。
亲和力预测模型AffinityEvaluator:这个模型可以判断给定的抗体能否结合到抗原表位,以及结合的概率有多高。这是一个核心模型,因为它需要准确判断哪些抗体能结合,哪些不能。
模拟抗体进化的模型AbEvolver:这个模型用于模拟和生成抗体亲和力成熟的进化路径,给定一条已经有一定亲和力的抗体,帮助我们预测哪些位点的突变可能提高亲和力。
成功案例展示
在科迈生物,该抗体从头设计流程已经得到了多个案例的成功验证。我们针对4个抗原靶点完成了抗体从头设计,结果表明,针对某个指定的抗原表位,利用AI从头设计包含1万条CDRH3的抗体,经过湿实验验证后,有数条抗体可以结合,亲和力KD的范围从几微摩尔到几纳摩尔不等,经过冷冻电镜、表位竞争等实验验证表位符合预期,而且在细胞层面有生物学功能。
该流程的设计成功率跟David Baker在2024年3月份发表的纳米抗体从头设计文章(Bennett N R, Watson J L, Ragotte R J, et al. Atomically accurate de novo design of single-domain antibodies[J]. bioRxiv, 2024.)报道的成功率相当。当然,在其他靶点上,该流程的适用程度和泛化能力需要进一步验证。
下面我们详细介绍一下这4个案例设计流程和湿实验结果:

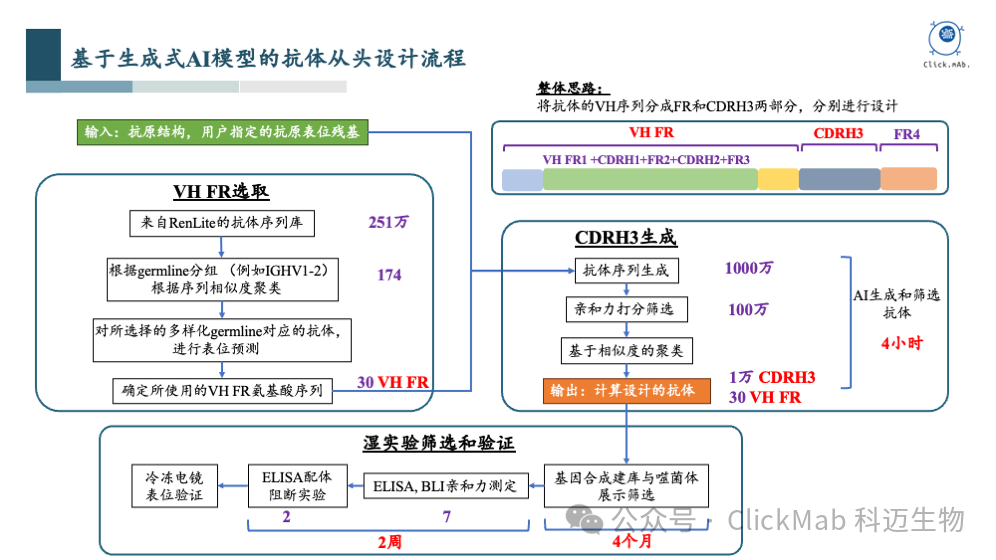
上图展示了我们的抗体从头设计流程。我们知道抗体是由重链和轻链组成的,在我们的设计中,轻链是固定不变的。这是因为我们使用的训练数据来自百奥赛图RenLite小鼠产生的全人源抗体,这意味着所有抗体的轻链序列是完全相同的,因此在设计时,轻链部分被固定下来,我们只专注于设计重链的可变区域。这种策略简化了模型的复杂度,因为我们只需要考虑重链的可变区域。
我们将重链的可变区域进一步细分为几个部分:VH框架区、CDR H1区、CDR H2区和CDR H3区。其中,VH框架区相对保守,而CDR H3区的多样性非常高,因此我们对这两部分采取了不同的设计策略。
我们采用了从已知序列中选取的策略。基于内部测序获得的数百万条数据,通过聚类分析,我们识别出了174种不同的VH框架区。然后,我们使用一个AI模型预测哪些VH框架区更有可能结合到特定的抗原表位,并从中筛选出大约30种可能合适的VH框架区。这一步骤是基于VH框架区的保守性,我们认为30种框架区足以代表所需的多样性。
我们采用了生成全新序列的策略。由于CDR H3区对于抗体与抗原表位的结合至关重要,我们单独设计了这一部分。在确定了VH框架区之后,我们使用生成模型来生成CDR H3区的序列。最终,我们生成了大约1000万个具有多样性的CDR H3序列,并通过亲和力预测模型进行筛选,最终筛选出约100万个序列。进一步聚类后,我们得到了1万条CDR H3序列。

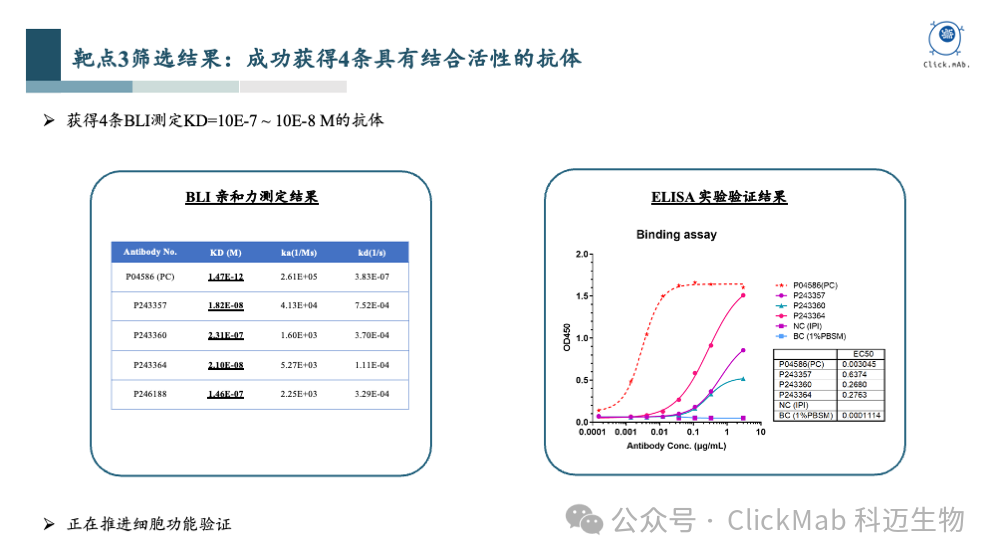
以上为靶点1更详细的实验数据,包括亲和力检测结果和阻断实验结果。亲和力检测显示,这些抗体的亲和力范围KD从10^-7 M到10^-9 M,已经基本可以满足抗体药物的需求。阻断实验证实了两条抗体能够有效地阻断天然配体的结合。

进一步的,我们验证了抗体的细胞活性。实验结果表明, AI设计的两条抗体可以抑制磷酸化转化信号通路,具有显著的生物学功能。
通过这个案例,我们可以看到从头设计的抗体以高亲和力结合到了指定的抗原表位上,而且具有生物学功能。这个案例是对平台能力的充分证明,完成了从分子结构到细胞功能的验证闭环。
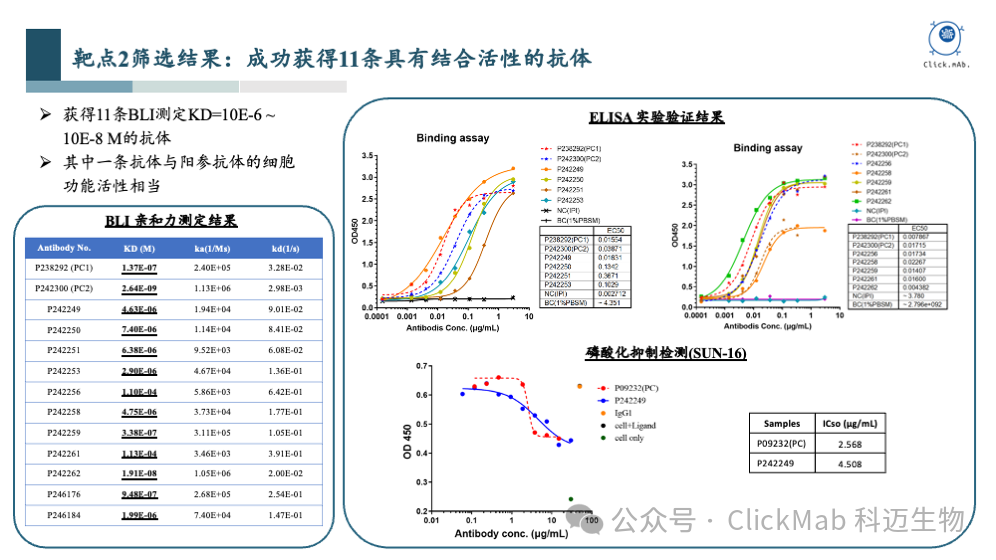
以上是靶点2的筛选结果,我们获得了11条从头设计的全新抗体,其中1条抗体的磷酸化抑制活性与阳参抗体相当。
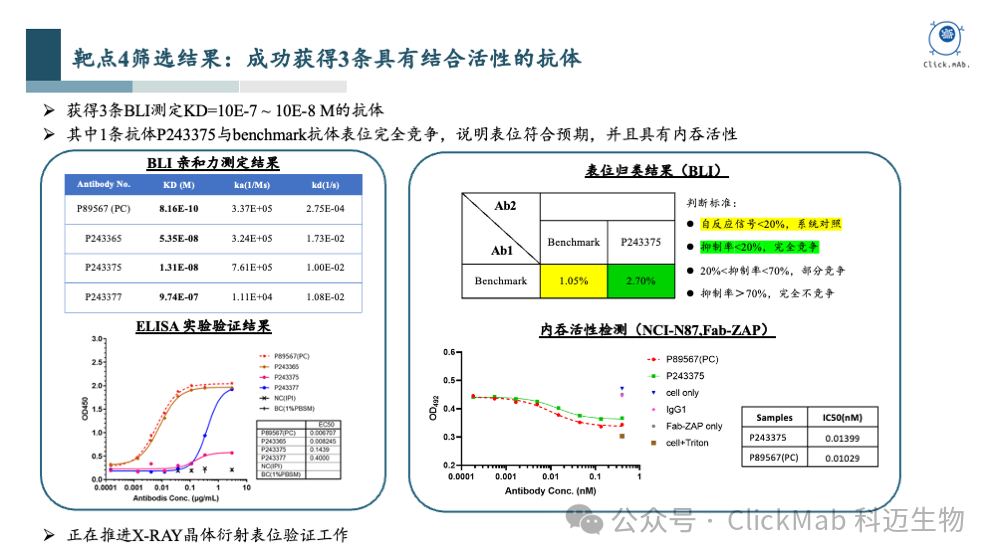
以上是靶点4的筛选结果,我们获得了3条从头设计的全新抗体, 其中1条抗体与阳参抗体有表位竞争,暗示表位符合预期, 因为冷冻电镜没有顺利获得复合物结构,我们正在推进X-ray晶体衍射的表位验证工作。靶点4是一个ADC相关的靶点,AI设计的这条抗体具有与阳参相当的内吞活性。
从以上四个案例的结果来看,AI抗体从头设计已经可以针对特定目标表位,获得一定程度上满足亲和力要求、具备生物学功能的抗体,完成了概念验证。

对于AI抗体从头设计来说,最大的优势在于能够精准控制抗体的抗原表位结合,可将此看作是一种新的抗体发现手段或工具。与传统的基于免疫的方法相比,这种方法避免了免疫过程中的随机性,从而更加精准可控,可实现抗体药物的理性设计。对于低免疫原性、高同源性而无法免疫小鼠获得抗体的蛋白,AI设计提供了新的解决思路。
有望解决抗体发现中极具挑战的难题
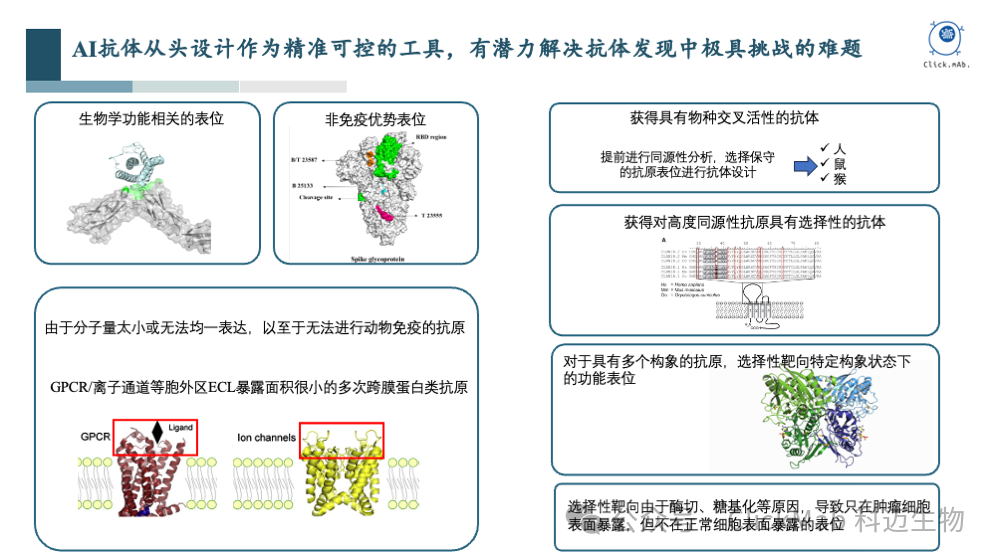
在抗体发现领域,存在一些传统方法难以解决的挑战,而特定表位AI抗体从头设计平台有希望解决这些问题:
生物学功能相关的表位:传统方法可能难以针对具有生物学功能的表位开发抗体,而AI可以利用其训练集中多样化的抗原表位数据,学习氨基酸层面的相互作用规律,从而设计出能够结合这些表位的抗体。
非免疫原性表位:一些表位可能因为免疫原性较低而难以通过传统免疫方法获得抗体。AI设计时,可以指定选择这些表位,从而设计出相应的抗体。 G蛋白偶联受体(GPCR)和离子通道等多次跨膜蛋白:GPCR是一类难以通过传统方法进行抗体开发的膜蛋白,因为它们的胞外区(ECR)暴露较少,且抗原难以表达制备。AI可以利用其对多样化表位的理解,设计出能够结合GPCR胞外区的抗体。 物种交叉活性:在研发针对人类抗原的抗体时,可能需要考虑其在动物模型中的活性。AI可以通过比较人类和其他物种的同源蛋白,选择保守性强的表位,或者根据表位的差异来设计抗体序列,设计出具有交叉活性的抗体。 高度同源性蛋白的选择性:对于具有高度同源性的蛋白家族,AI可以在设计时考虑不同家族成员的序列和结构差异,预测并选择能够特异性结合目标蛋白的表位。 多构象蛋白的结合:一些蛋白能存在多种构象,传统免疫方法无法控制最终结合的构象。AI可以在充分理解蛋白结构和功能的基础上,理性地选择特定的构象和表位进行设计。 肿瘤特异性表位:在肿瘤免疫治疗中,需要设计能够区分肿瘤细胞和正常细胞的抗体,以减少对正常组织的毒性。AI可以识别肿瘤细胞表面特有的表位,设计出具有肿瘤特异性的抗体。
抗体从头设计的未来发展趋势
参考文献
Zambaldi V, La D, Chu A E, et al. De novo design of high-affinity protein binders with AlphaProteo[J]. arXiv preprint arXiv:2409.08022, 2024.
Cocco S, Feinauer C, Figliuzzi M, et al. Inverse statistical physics of protein sequences: a key issues review[J]. Reports on Progress in Physics, 2018, 81(3): 032601.
Gao X, Cao C, He C, et al. Pre-training with a rational approach for antibody sequence representation[J]. Frontiers in Immunology, 15: 1468599.
Bennett N R, Watson J L, Ragotte R J, et al. Atomically accurate de novo design of single-domain antibodies[J]. bioRxiv, 2024.
关于科迈生物
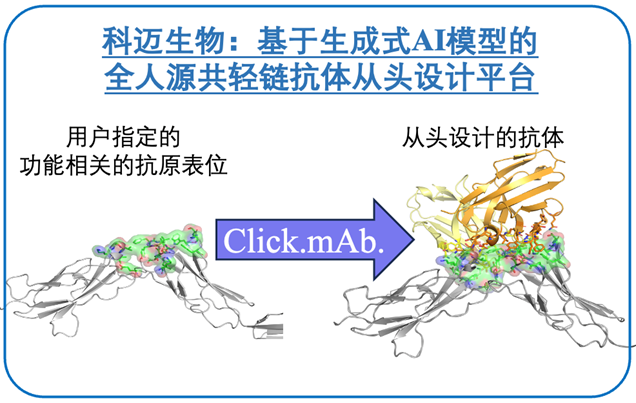
科迈生物是一家专注于利用生成式 AI 模型进行抗体设计的科技生物企业,创始股东为晶泰科技和百奥赛图,于 2021 年 6 月成立,并于当年 9 月完成了近千万美元种子轮融资。科迈生物基于深度学习技术,在以内部积累的大量配对抗原、抗体序列及结构数据进行训练的基础上,形成基于指定抗原表位生成高亲和力、全人源共轻链抗体的数据驱动的差异化抗体发现解决方案,旨在解决当前抗体药物的早期发现中,对于特定的功能表位、低免疫原性表位、高度同源和保守表位、特定构象的表位、难以表达制备和免疫的抗原等场景下的抗体难以获得的问题。在多个内部测试案例中,Click.mAb. 平台针对指定的抗原表位生成了具备高亲和力(例如 KD 优于 10nM)的抗体,且通过冷冻电镜获得的抗原-抗体复合物结构表明,抗原表位符合预期。

往期文章
Click.mAb. AI平台正式上线,一键抗体设计时代来临!
喜讯 | 科迈生物参与的“十四五”国家重点研发计划“前沿生物技术”重点专项获批立项

发表评论